Key takeaways
OpenAI’s first open‑weight model since GPT‑2, GPT‑OSS is strong, practical and genuinely useful, but it doesn’t consistently top today’s leaderboards. In this post I’ll show where GPT‑OSS shines and where it lags behind leading open models like Qwen 3, DeepSeek R1/V3, Kimi K2 and others. We’ll also look at how to pick the right model for your use case, why open models matter and how the U.S. can keep pace.
OpenAI is finally “open”, again! They released an open weight version of their GPT-2 model back in the day (2019), but since then it’s been nothing but proprietary models all the way. Until now…
GPT-OSS is an open weight model that is on par with GPT-4 as well as many of the other open weight models like Qwen 3, DeepSeek R1/V3 and Kimi K2. It’s not quite at the top of all the leaderboards (as GPT-5 is), but compared to other open US models like Llama and Gemma, it has certainly come to play.
We’re going to look at where GPT-OSS shines, where it lags, why open models are important and how the U.S. can continue to keep pace with China.
GPT-OSS is pretty smart
With the release of GPT-OSS, OpenAI has closed the gap with leading open weight models such as Qwen 3, DeepSeek R1/V3, Kimi K2 and Llama across almost every benchmark and has regained the throne as the top dog in the U.S.-based open weight LLM space.
Here are charts from some of my favorite leaderboards, which test everything from reasoning to coding ability, so you can see how GPT-OSS stacks up against the competition.
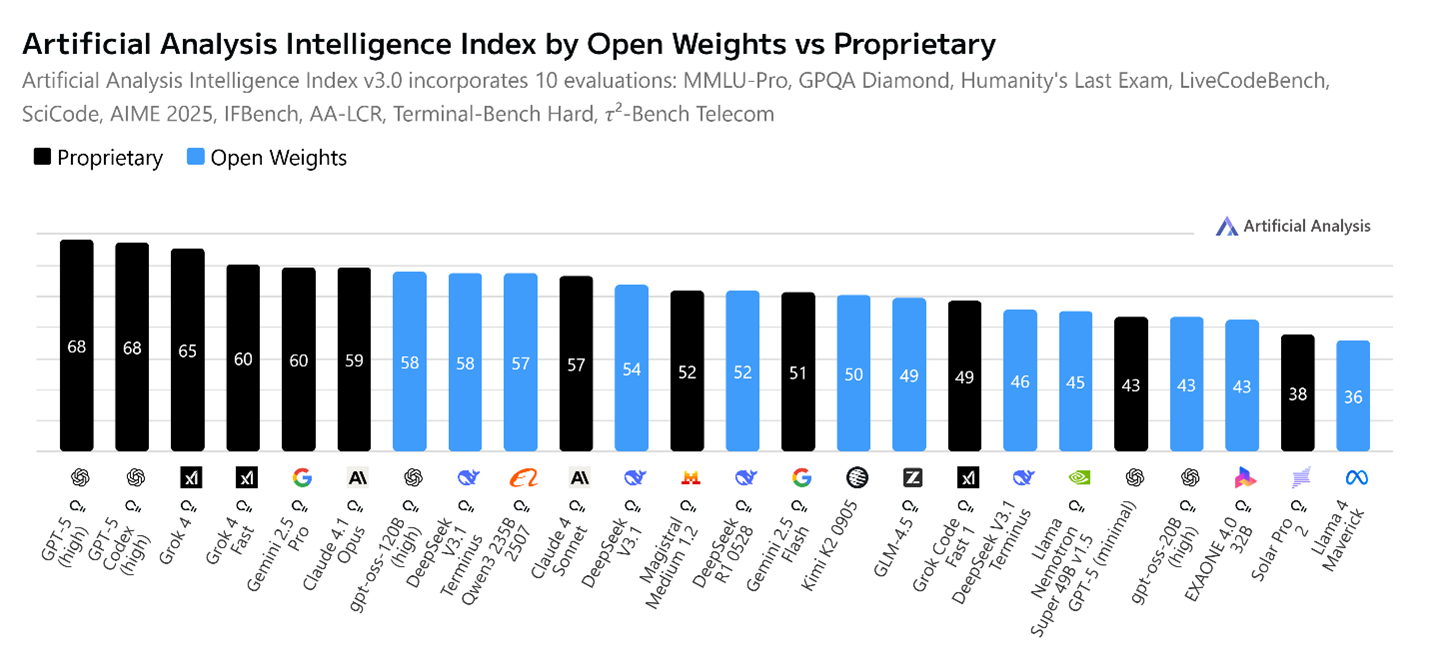
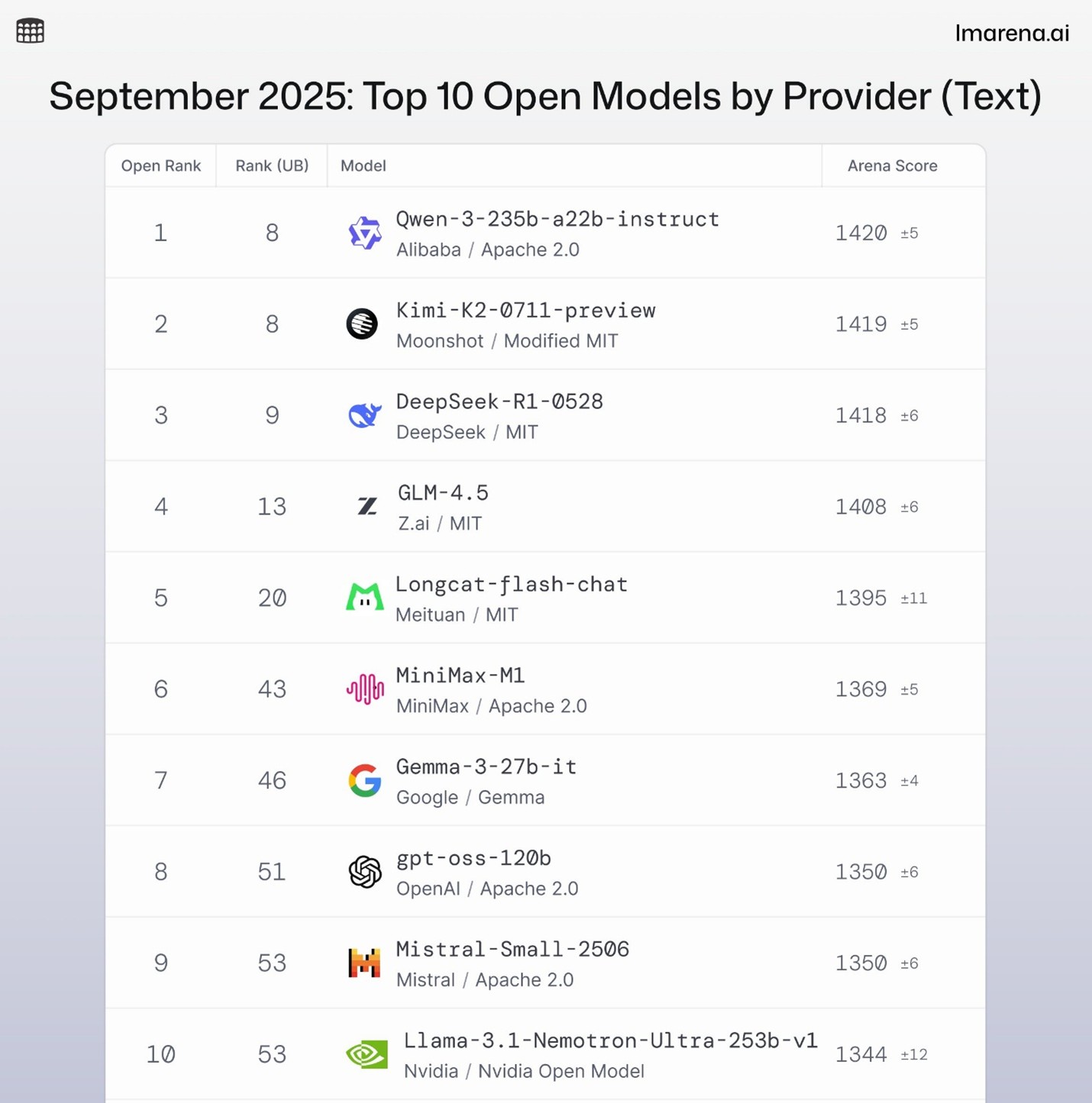
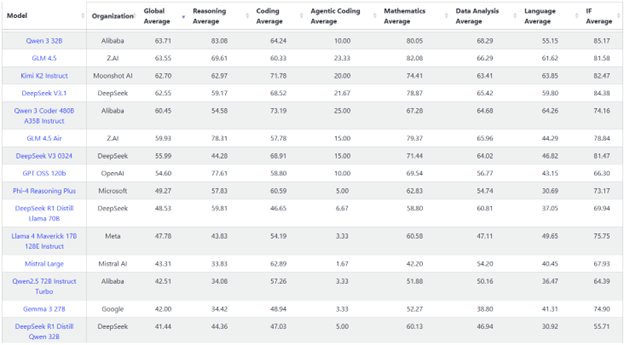
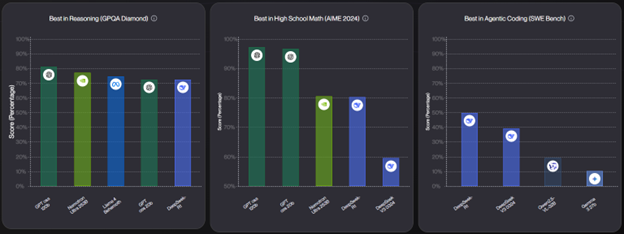
While there were several issues with the release of GPT-5, namely the challenges with its internal router that decides how much thinking to do, as well as the positioning of it as a true AGI, GPT-OSS has not suffered from the same problems. Partly, this is because GPT-OSS doesn’t include a router. There are simply two versions, gpt-oss-120b and gpt-oss-20b. Both are reasoning models with excellent instruction following and tool use, making them extremely useful for many agentic tasks.
Why open models matter
Open models, including models that are open weight (where the model weights, also known as the trained parameters, are made available to download and use) and open source (where not just the model weights but also the training data, methodology, code and architecture are shared) allow the community to benefit from the research that goes into building the models. These models can also be downloaded and used, essentially for free, as opposed to the pay-per-token licensing model of proprietary models like ChatGPT, Claude or Gemini. Finally, open models can be modified, either via a process called fine tuning, where additional training is done to help them perform better in certain domains, or via distillation, where the essence of the model’s knowledge and intelligence is retained, yet they can run on less powerful hardware at the cost of slight degradation in performance.
In addition to the above, the development of open models ensures that Artificial Intelligence does not remain the domain of a few large corporations that control the entire ecosystem. This is very much in parallel to the open source software movement that has allowed Linux to power much of the world’s economy rather than relying on companies like Microsoft or Oracle.
Where GPT‑OSS stacks up vs. Qwen 3, DeepSeek R1/V3 & Kimi K2
Let’s take a look at how these leading open weight models compare and why you might want to pick one over another for a particular task.
GPT-OSS (OpenAI) — Text‑only, efficient, easy to run
- Pros: This is the flagship open weight model from OpenAI and leverages much of the same training techniques that make GPT-5 so powerful. Because it comes in two “sizes,” it can run on both high-end and low-end hardware.
- Cons: Not top of every public benchmark, text‑only (no native vision/audio).
DeepSeek R1/V3 (Deepseek) — Reasoning at the frontier, frequent releases
- Pros: The R1 and V3 families put open‑weight frontier reasoning in your hands. These models have been widely adopted as a baseline for “thinking” models and have strong math and coding “vibes.”
- Cons: DeepSeek is not the most transparent about data collection and exhibits censorship, especially around topics related to China.
Qwen 3 (Alibaba Cloud) — Full stack, many sizes, broad tooling
- Pros: Qwen has been releasing updated models on practically a weekly basis, and they have vision models and coding models besides just text only language models.
- Cons: Not all of their models have the same licensing method, and there are so many of them that picking the right one requires a lot of research and homework.
Kimi K2 (Moonshot) — A “YOLO run” that hit hard
- Pros: Kimi K2 made a splash with an experimental training recipe and strong real‑world performance and has been gaining momentum as a reasoning‑oriented open model.
- Cons: Licensing is modified‑MIT which is less permissive than the Apache license other models offer. There are fewer size options than Qwen, and documentation is improving but still uneven.
Takeaway: If you need a locally hosted model that is trustworthy and simple to deploy, GPT‑OSS is a great option. If you need frontier reasoning or multimodal capabilities, today’s top scores often come from China. Just be aware that their data collection, privacy and censorship standards differ widely from what we expect in the U.S. China has been pulling far ahead of U.S. efforts recently, and with the release of GPT-OSS, we are only barely keeping up. This is a big problem because the countries that have access to the most powerful open weight and open source models are the ones that will control the future.
How the U.S. can keep pace with China
If the U.S. wants to keep pace with China, we will need to do several important things:
- We must fund fully-open source reference models and data. A good example is OLMo, a model where everything, including weights, data, code, algorithms, etc. are made publicly available under a permissive license.
- We must provide sustained compute access for academia and startups. Training models takes a tremendous amount of processing time, and only governments can afford to cover the costs in non-commercial applications.
- We need to develop a public policy that supports open innovation while managing risk. A great example of this is Nathan Lambert’s American DeepSeek AKA ATOM (American Truly Open Models) push: an open coalition to build truly open U.S. models with competitive performance to Chinese options.
Conclusion
If you can take away one thing from this post, it’s this: GPT‑OSS is a welcome, practical step that makes local, well‑behaved text models easy to adopt. But in 2025, “best open model” depends on the job: DeepSeek/Qwen/Kimi/GLM often lead on raw capability (and compute), while GPT‑OSS nails frictionless, policy‑friendly deployment. The real win for all of us is a vibrant, open ecosystem – transparent models, clear licenses, and healthy competition. Let’s make sure that the U.S. stays in the game and ultimately leads the way down this very exciting path!
Thank you all for tuning in. Please subscribe to be notified whenever a new post comes out, and we look forward to seeing you on the next one.
Stay curious, my friends!
-David
Disclaimer
This article is for general information purposes only. The opinions, analysis and commentary expressed are not and cannot be relied on as legal advice, and do not necessarily reflect the views of Yardi Systems, Inc., or any of its affiliates.